A Brief History of Sentence Representation in NLP

Illustration from dribbble, all rights owned by Gleb Kuznetsov✈, Link.
This blog post is to summarize the brief history of sentence representation in the natural language processing area.
Sentence Embedding / Sentence Representation: These are representation of sentences in a n-dimensional vector space so that semantically similar or semantically related sentences come closer depending on the training method.
1. The Usage of Sentence Representation
The Tao of sentence representation in industry:
- The same embedding can be used cross-domain;
- Fine-tune the pre-trained embedding to use in products.
Specifically, you can decide either:
- Use the embedding directly and train the classifier without caring about the embedding;
- OR Retrain the embedding models along with the classifier. e.g. BERT
BERT everywhere: BERT is already widely used in all kinds of industrial applications. BERT as a breakthrough may be the peak of word/sentence representation, hence many of the papers published in Neurips 2019 are based on BERT instead of proposing new methods.
2. The History of Sentence Representation
2.1 Traditional Sentence Representation
One-hot Bag of Words (BoW): Each word is linked to a vector index and marked as 0 or 1 depending on whether it occurs in a given sentence [1]. For example:
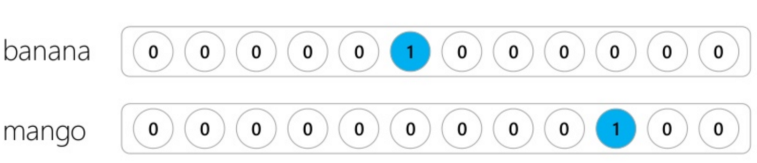
banana mango is encoded as 000001000100;
mango banana is encoded as 000001000100.
- Pro: Simple and fast;
- Con: No word order; No semantic information; No difference between important words and non-important words.
Term Frequency-Inverse Document Frequency (TF-IDF): is a method to represent how important a word is in a corpus. It provides a weight to a given word based on its context it occurs. More about TF-IDF in [2]. Pic below is from [2].

- Pro: Simple and fast; consider the importance of word;
- Con: No word order information; No semantic information.
2.2 Neural Embeddings
Language Model. A language model describes the probability of a text existing in a language. For example, the sentence “I like eating bananas” would be more probable than “I like eating convolutions.” We train a language model by slicing windows of n words and predicting what the next word will be in the text.
Word2Vec / Doc2Vec: Word2Vec [3] - contains 2 models which the first one (Continuous Bag of Words, CBoW) is using the previous words to predict the next word and the other model (Skip-Gram) uses 1 word to predict all surrounding words. Doc2Vec [4] - is to create a numeric representation of a document, regardless of its length. Based on the Word2Vec model, they added another vector called Paragraph ID to the input of CBoW. The new vector acts as a memory that remembers what is missing from the current context or as the topic of the paragraph [5]. Recommend to read [5] for more information.

Other than Word2Vec, there are multiple other unsupervised ways of learning sentence representations. Listed below.
Autoencoder: is an unsupervised deep learning model that attempts to copy its input to its output. The trick of autoencoders is that the dimension of the middle-hidden layer is lower than that of the input data. Thus, the neural network must represent the input in a smart and compact way in order to reconstruct it successfully [6].
RNN / LSTM: Character level LSTM (my favorate LSTM article, by Andrej Karpathy) [7] and Bidirectional-RNNs [8].
Skip-thought: The same intuition of language model predicting the next from previous. Yet instead of predicting the next word or next character, it's predicting the previous and next sentence. This gives the model more context for the sentence, thus we can build better representations of sentences. [6] More on Skip-Thoughts in [9].
Attention and Transformer: Attention takes two sentences, turns them into a matrix where the words of one sentence form the columns, and the words of another sentence form the rows, and then it makes matches, identifying relevant context. This is very useful in machine translation. Self-Attention: put the same sentence as the colum and row, we can learn how some part of the sentence relate to the other part. A good use case is to help understanding what "it" is referring to, i.e. Linking pronouns to antecedents [10].
While attention was initially used in addition to other algorithms, like RNNs or CNNs, it has been found to perform very well on its own. Combined with feed-forward layers, attention units can simply be stacked, to form encoders. Moreover, Attention's "spotlight" can help focus on the actually useful data comparing with LSTM.
Attention is All you Need (Vaswani, et al., 2017) [11] is the influencer proposing Transformer allowing us to do Seq2Seq without a recurrent unit. It's based on Key, Value, Query and stack of encoders / decoders. This is explained in detail in [12].

BERT: It tells its idea from the name - Bidirectional Encoder Representations from Transformers, which suggests that the key technical innovation is applying the bidirectional training of Transformer. The pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks [13]. More explaination on BERT can be found here [14]. Also BERTViz for visualizing BERT [15].
[1] Aaron (Ari) Bornstein, Beyond Word Embeddings Part 2, Medium
[2] Chris Nicholson, A Beginner's Guide to Bag of Words & TF-IDF, Skymind
[3] T. Mikolov, et, al., Efficient Estimation of Word Representations in Vector Space
[4] Quoc V. Le and T. Mikolov, Distributed Representations of Sentences and Documents
[5] Gidi Shperber, A gentle introduction to Doc2Vec, WISIO
[6] Yonatan Hadar, Unsupervised sentence representation with deep learning, YellowRoad
[7] Andej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks
[8] Bidirectional recurrent neural networks, Wikipedia
[9] Sanyam Agarwal, My thoughts on Skip-Thoughts
[10] Chris Nicholson, A Beginner's Guide to Attention Mechanisms and Memory Networks, Skymind
[11] Vaswani, et al., Attention Is All You Need, NIPS 2017
[12] Ta-Chun (Bgg) Su, Seq2seq pay Attention to Self Attention: Part 2
[13] J. Devlin, et, al., BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[14] Rani Horev, BERT – State of the Art Language Model for NLP, LyrnAI